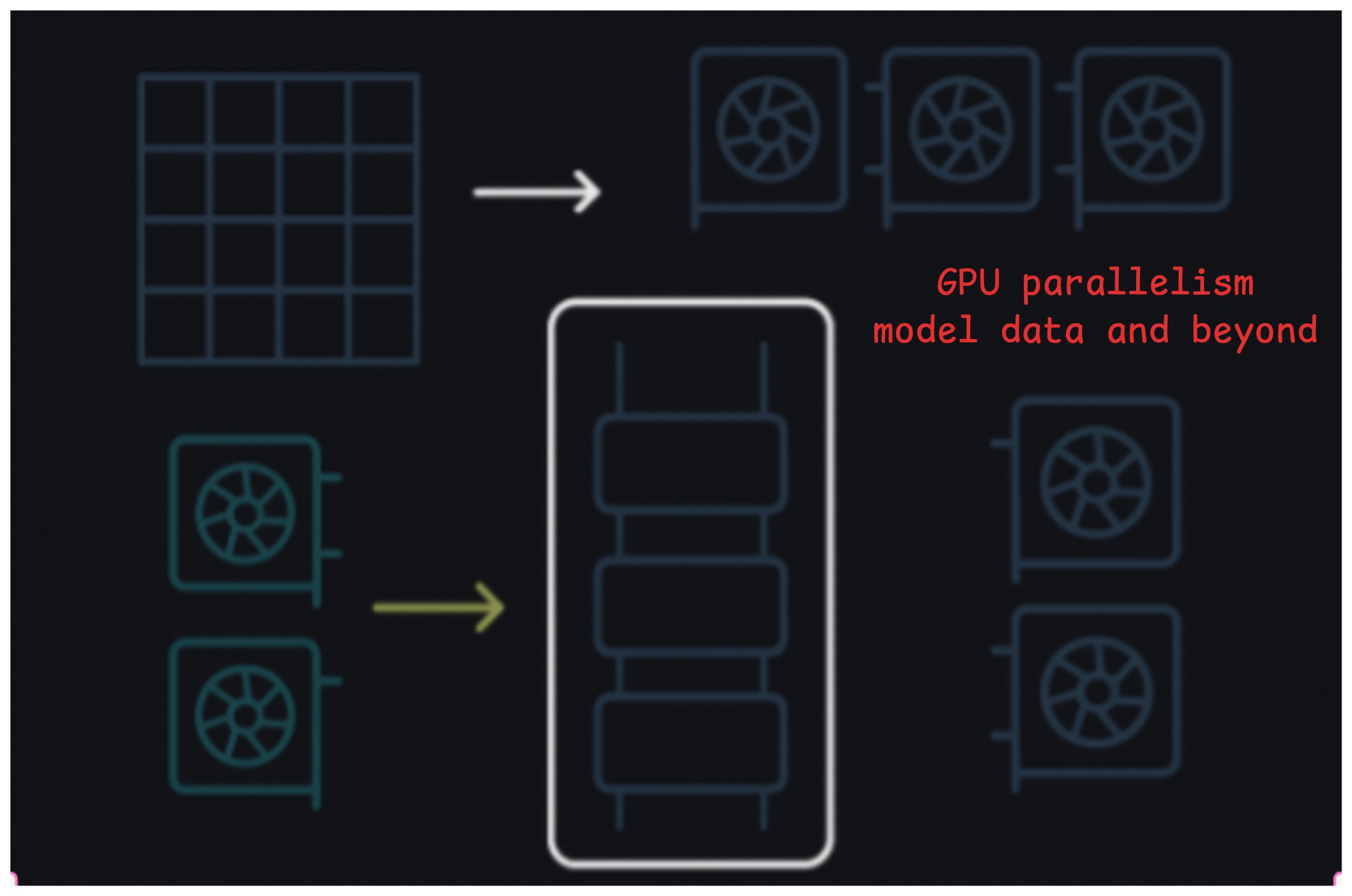
Understanding multi GPU Parallelism paradigms
We’ve been talking about Transformers all this while. But how do we get the most out of our hardware? There are two different paradigms that we can talk about here. One case where your model happil...
We’ve been talking about Transformers all this while. But how do we get the most out of our hardware? There are two different paradigms that we can talk about here. One case where your model happil...

An intuitive build up to Attention and Transformer
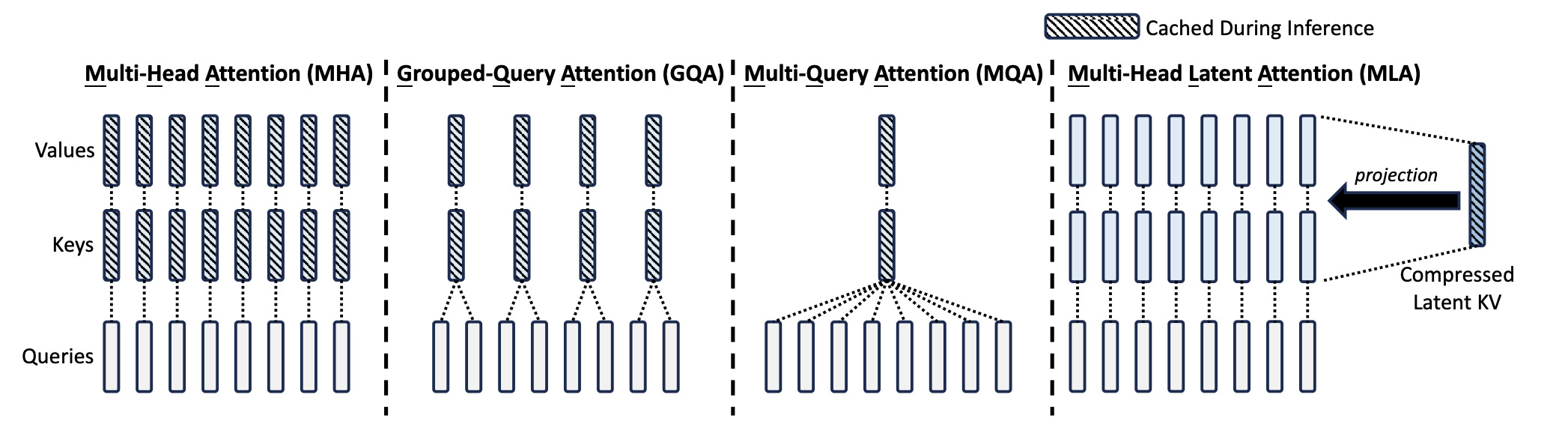
Comparing various transformer architectures like MHA, GQA, Multi Latent Attention, nGPT, Differential Transformer.
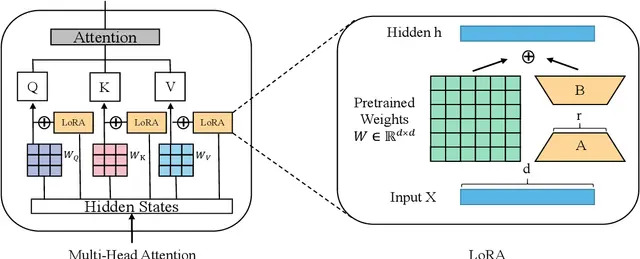
A better initialisation for LoRA to make convergence faster