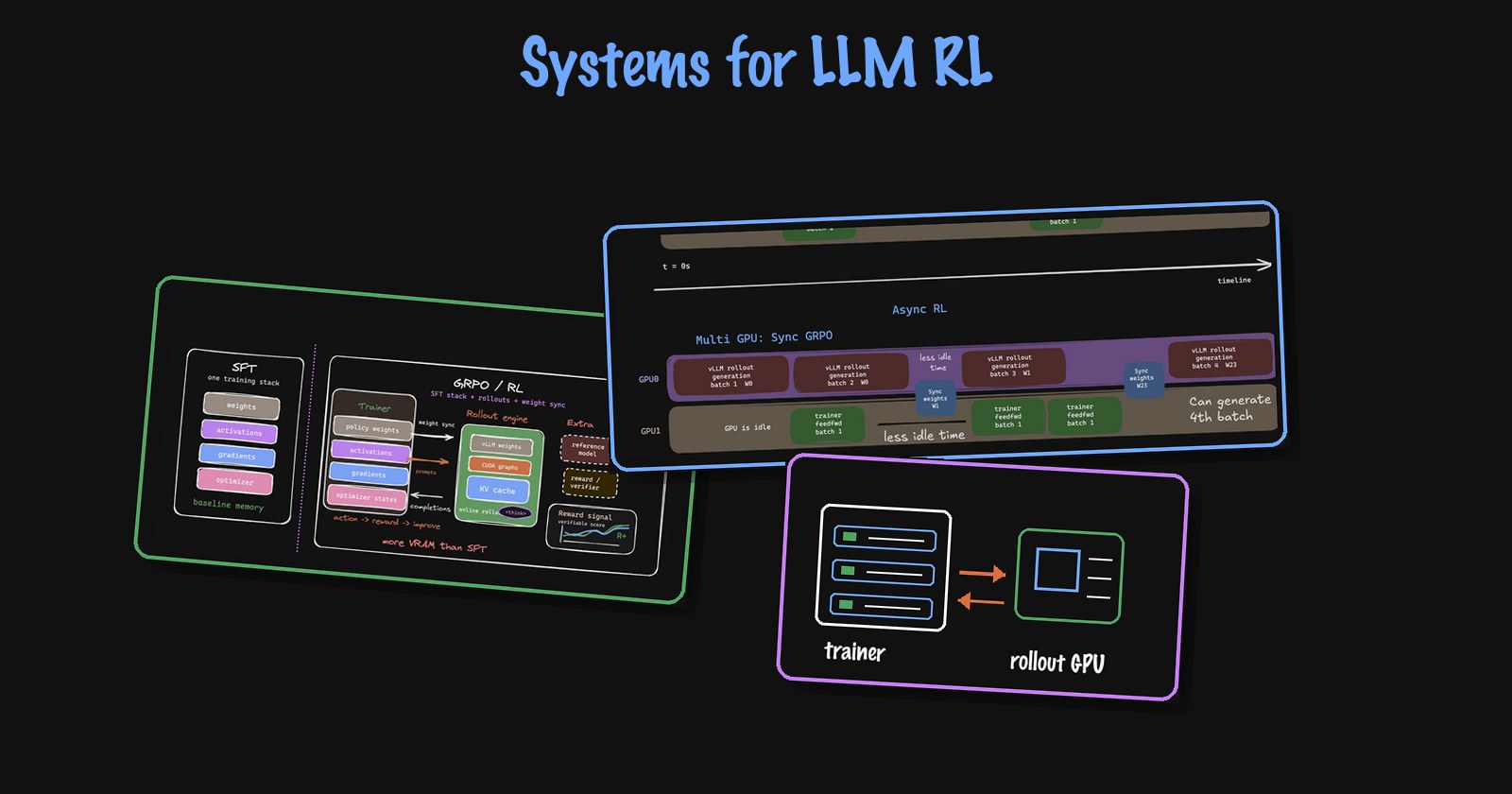
Systems for LLM RL
Foray into the systems challenges and approaches for LLM RL
First-principles explanations of attention, fine-tuning, GPU kernels, and the engineering details behind modern deep learning systems.
Foray into the systems challenges and approaches for LLM RL
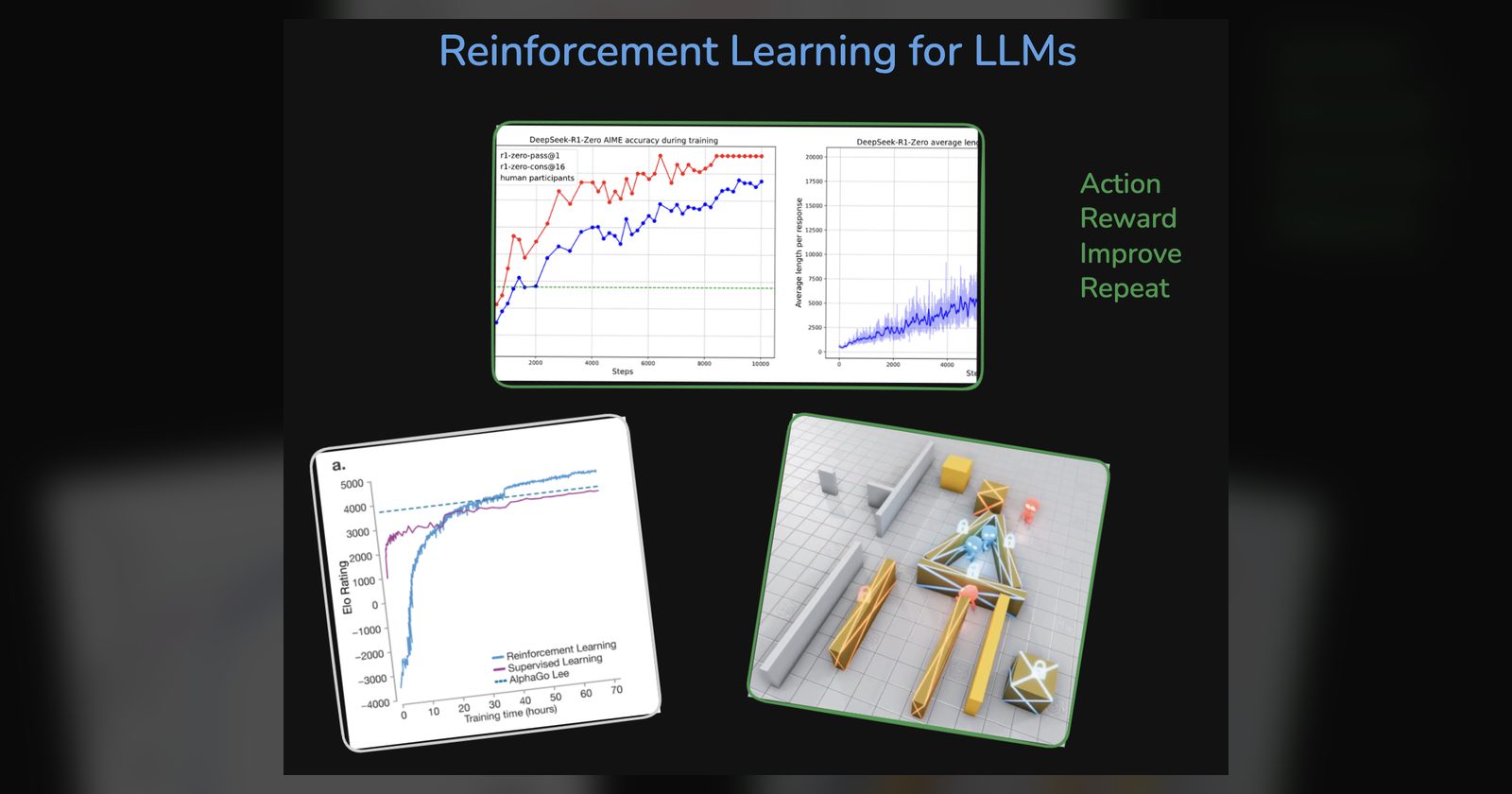
A brief introduction to reinforcement learning for LLMs
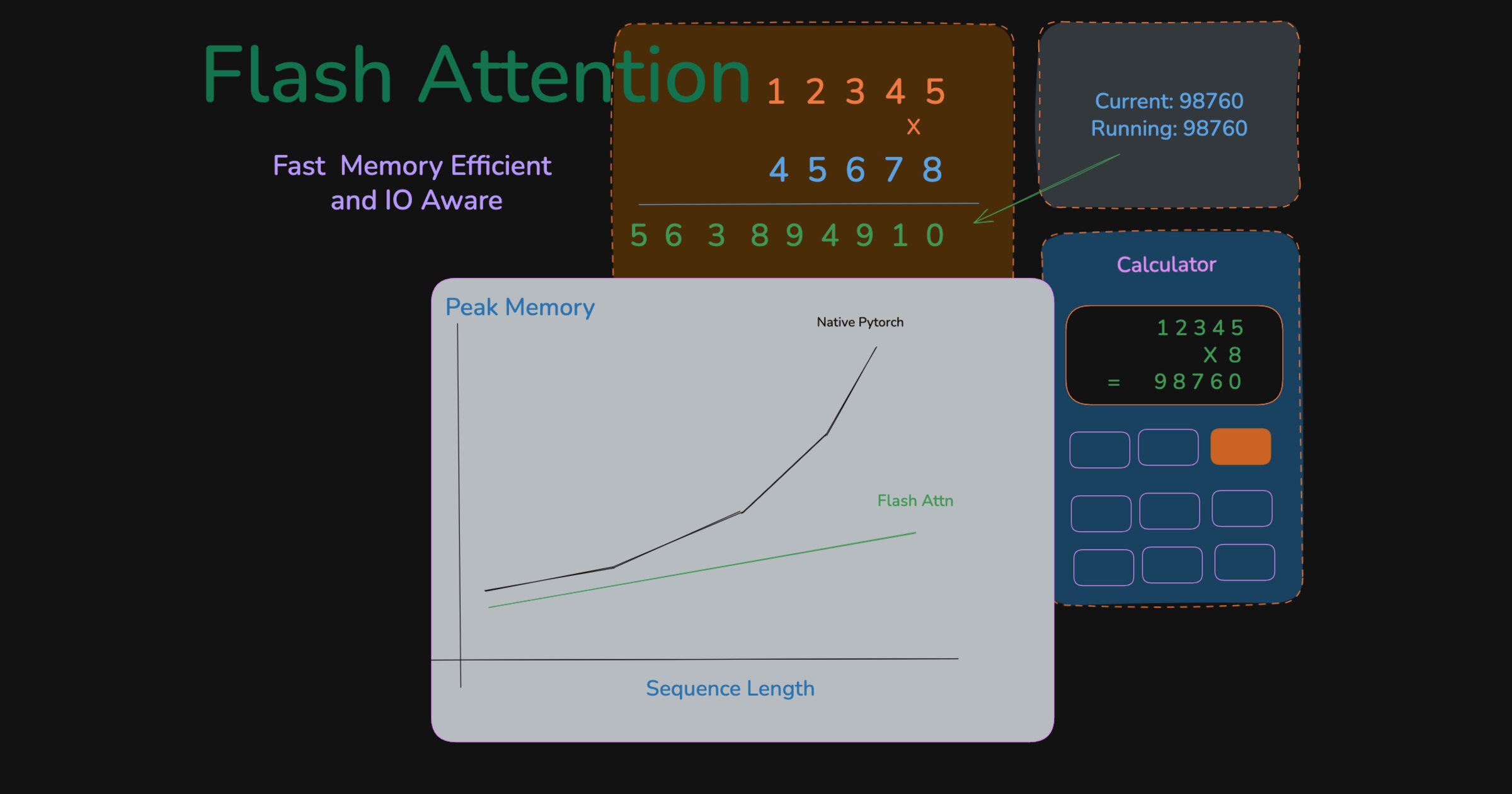
Fast and memory efficient exact attention
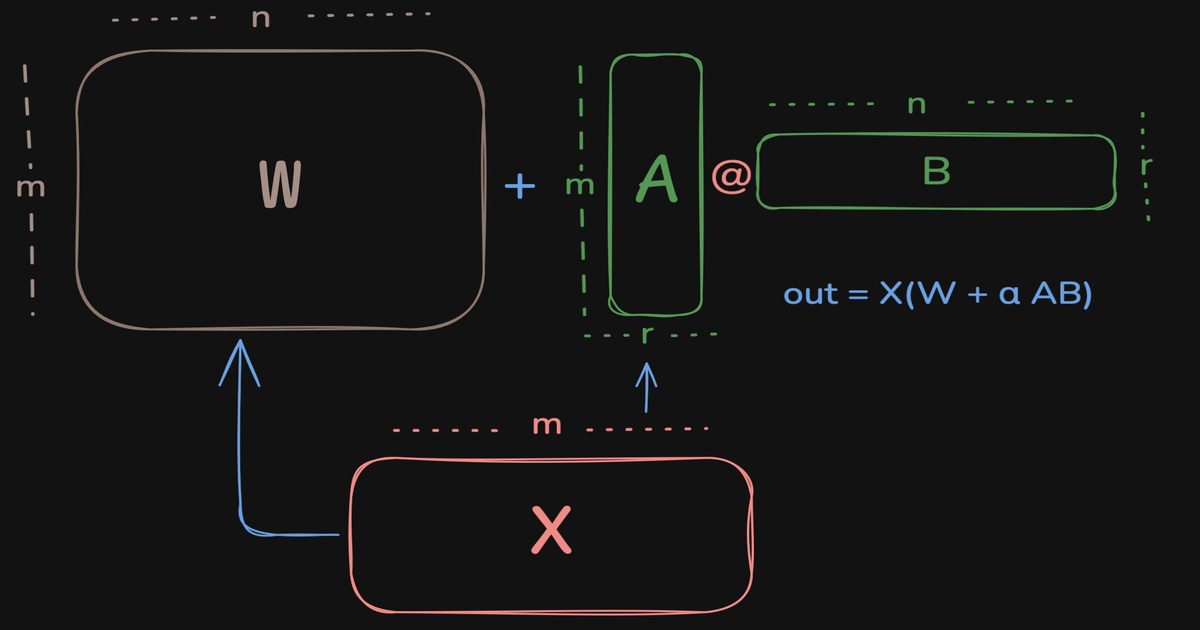
LoRA imagined from the ground up
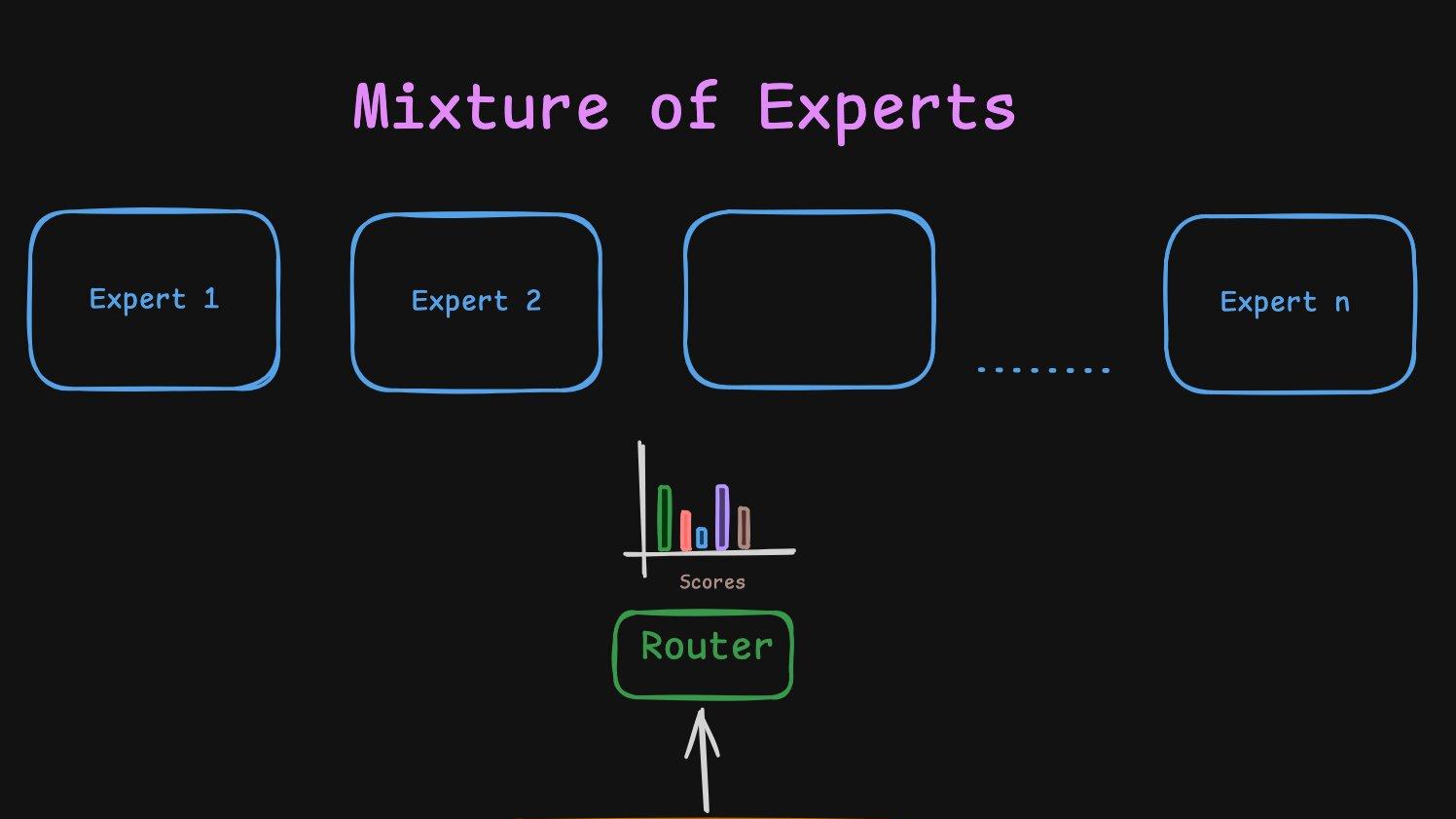
An intuitive build up to Mixture of Experts
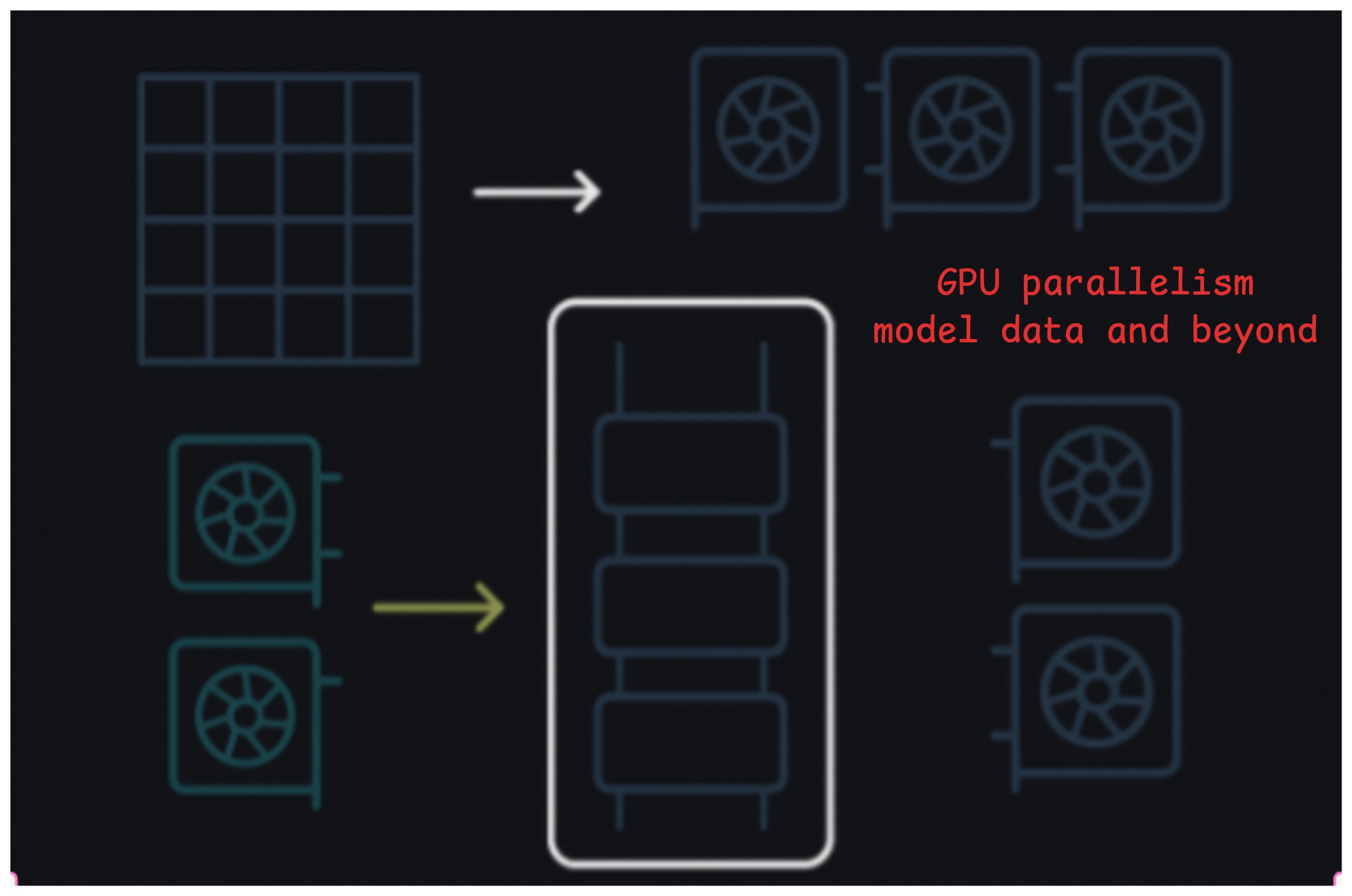
A practical guide to data, tensor, and pipeline parallelism for LLM inference and training

An intuitive build up to Attention and Transformer
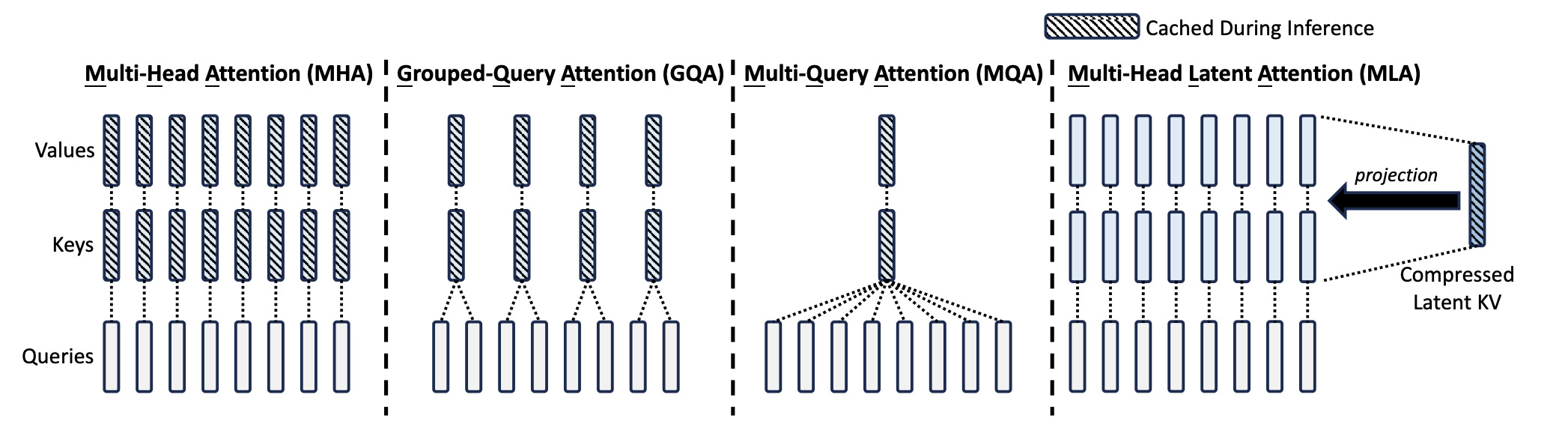
Comparing various transformer architectures like MHA, GQA, Multi Latent Attention, nGPT, Differential Transformer.
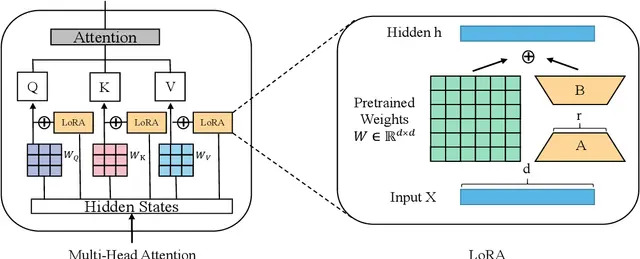
A better initialization for LoRA to make convergence faster